
Samuel Clay is a grad student in the schools of design and of engineering at Harvard. He founded NewsBlur, a personal RSS news reader, and Turn Touch, beautiful control for the smart home.
Talk to him @samuelclay.
Samuel Clay is a grad student in the schools of design and of engineering at Harvard. He founded NewsBlur, a personal RSS news reader, and Turn Touch, beautiful control for the smart home.
Talk to him @samuelclay.
Last week I submitted my project, NewsBlur, a feed reader with intelligence, to Hacker News. This was a big deal for me. For the entire 16 months that I have been working on the project, I was waiting for it to be Hacker News ready. It’s open-source on GitHub, so I also had the extra incentive to do it right.
And last week, after I had launched premium accounts and had just started polishing the classifiers, I felt it was time to show it off. I want to show you what the Hacker News effect has been on both my server and my project.
When I wasn’t writing code on the subway every morning and evening, I would think about what the reaction on Hacker News would be. Would folks find NewsBlur too buggy? Would they be interested at all? Let me tell you, it’s a great motivator to have an audience in mind and to constantly channel them and ask their opinion. Is a big-ticket feature like Google Reader import necessary before it’s Hacker News ready? It would take time, and time was the only currency which I could pay with. In my mind, all I had to do was ask. (“Looks cool, but if there’s no easy way to migrate from Google Reader, this thing is dead in the water.”)
Kurt Vonnegut wrote: “Write to please just one person. If you open a window and make love to the world, so to speak, your story will get pneumonia.” (From Vonnegut’s Introduction to Bagombo Snuff Box.)
Let’s consider Hacker News as that “one person,” since for all intents, it is a single place. I wasn’t working to please every Google Reader user: the die-hards, the once-in-a-seasons, or the twitter-over-rss’ers. For the initial version, I just wanted to please Hacker News. I know this crowd from seeing how they react to any new startup. What’s the unique spin and what’s the good use of technology, they would ask. What could make it better and is it good enough for now?
If you’re outsourcing tech and just applying shiny visuals to your veneer, the Hacker News crowd sniffs it out faster than a beagle in a meat market. So I thought the best way to appeal to this crowd is to actually make decisions about the UI that would confuse a few people, but enormously please many people. From comments on the Hacker News thread, it looks like I didn’t wait too long.
Have I got some graphs to show you. I use munin, and god-love-it, it’s fantastic for monitoring both server load and arbitrary data points. I watch the load on CPU, load average, memory consumption, disk usage, db queries, IO throughput, and network throughput (both to external users and to internal private IPs).
I also have a whole suite of custom graphs to watch how many intelligence classifiers users are making, how many feeds and subscriptions users are adding, the rate of new users, premium users, old users returning, new users sticking around, and load times of feeds (rolling max, min, and average).
Used to be that when a thundering herd of visitors came to NewsBlur, I’d have to watch the server nervously, as CPU would smack 400% (on a 4-core machine), the DB would thrash on disk, and inevitably some service or another would become overrun.
Let’s see the CPU over the past week:
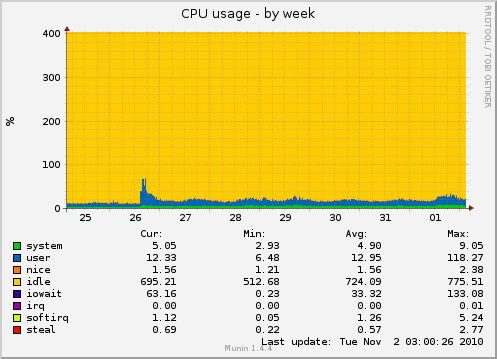
Spot the onslaught? NewsBlur’s app server is only responsible for serving web requests, queueing feeds to be updated, and calculating unread counts. Needless to say, even with nearly a thousand new users, I offloaded so much of the CPU-intensive work to the task servers that I didn’t have a single problem in serving requests.
This is a big deal. The task server was overwhelmed (partially due to a bug, but partially because I was fetching tens of thousands of new feeds), but everybody who wanted to see NewsBlur still could. Their web requests, and loading each feed, were near instantaneous. It was wonderful to watch it happen, knowing that everybody was being served.
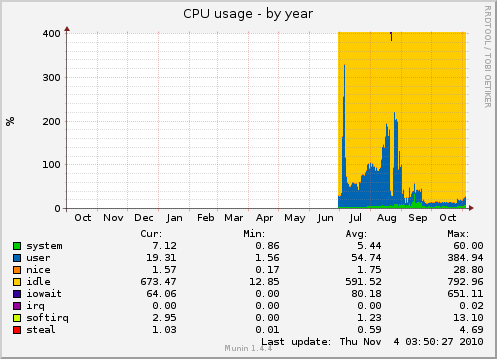
Clearly, bugs have been fixed, and CPU-intensive work has been offloaded to task servers.
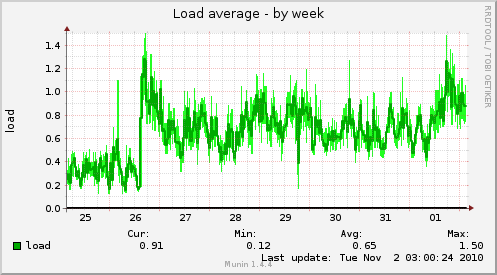
The load of the server went up and stayed up. Why did it not fall back down? Because the app server is calculating unread counts, it has more work to do even after the users are gone. This will become a pain point when one app server is not enough for the hundreds of concurrent users NewsBlur will soon have. But luckily, app servers are the easiest to scale out, since each user will only use one app server at a time, so the data only has to be consistent on that one server, as it propagates out to the other app servers (which may become db shards, too).
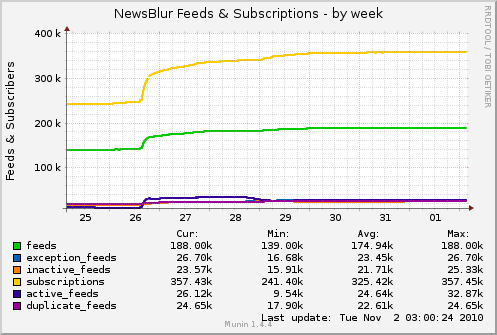
Economies of scale. The more feeds I have, the more likely a subscription to a feed will be on a feed that already exists. I want that yellow line to run off into space, leaving the green line to grow linearly. It’s fewer feeds to fetch.
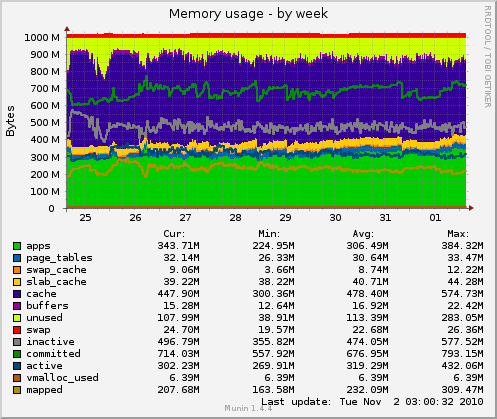
Memory doesn’t move, because I’m being CPU bound. I’m not actually moving all that much more data around. I use gunicorn to rotate my web workers, so NewsBlur’s few memory leaks can be smoothed over.
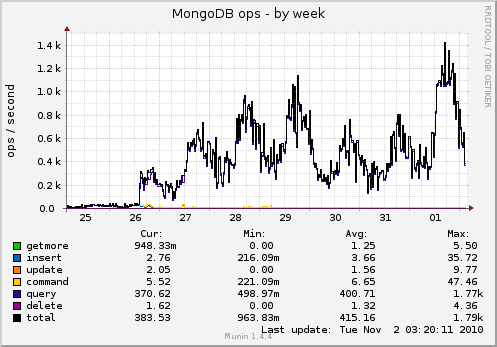
I use MongoDB to serve stories. All indexes, no misses (there’s a graph for this I won’t bother showing). You can extrapolate traffic through this graph. Sure, you don’t know average feeds per user, but you can take a guess.
In order to build all of the separate pieces, I broke everything down into chunks that could be written down and crossed off. Literally written down. I have all of my priorities from the past 7 months. It’s both a motivator and estimator. I’ve learned how to estimate work load far better than back in May, when these priorities start. I finish more of what I tried to start.
The way it works is simple: write down a priority for the month it’s going to be built in, number it, then cross it off if it gets built before the end of the month. You get to go back and see how much you can actually do, and what it is you wanted to build. This means I’m setting myself up for a pivot every month, when I re-evaluate what it is I’m trying to build.
Lastly, what more could you ask for? A prominent competitor, known to every Gmail user as the empty inbox link. Feed reading is a complicated idea made simple by having most users already exposed to a product that fulfills the feed reading need. By improving over that experience, users can directly compare, instead of having to learn NewsBlur on top of learning how to use RSS and track every site you read.
If your space has a major competitor and the barrier to entry is an OAuth import away, then consider yourself lucky. Anybody can try your product and become paid customers in moments. It’s practically a Lotus123 to Excel import/export, except you don’t need to buy the software before you try it out.
I’m half-way to being profitable. I only need 35 more premium subscribers. But so far, people are thrilled about the work I’m doing. Here are some tweets from a sample of users:



I’m e-mailing blogs, chatting with folks who have a blog influence, and most importantly, continuing to launch new features and fix old ones. Thanks to Hacker News, I get to appeal to a graceful and sharp audience. And good looking.
I’m on Twitter as @samuelclay, and I’d love to hear from you.